
「データ構造」と「アルゴリズム」と聞くけど難しそうだな。。
自分には理解できるだろうか。。
「データ構造」と「アルゴリズム」初めて聞く方にとっては、少し難しく感じるかもしれません。この記事では、図解や身近な例を用いて分かりやすく説明していきます。
データ構造とアルゴリズムは、効率的なプログラムを作成する上で欠かせない要素です。データ構造は情報をどのように整理し保存するかを定義し、アルゴリズムはその情報をどのように処理するかを決定します。
これらの概念を理解することで、プログラムの性能を大幅に向上させることができます。
この記事を通じて、プログラミングスキルを次の段階に引き上げていきましょう。
- データ構造とアルゴリズムの基礎が理解できる
- 適切なデータ構造とアルゴリズムの組み合わせを使い効率的な処理ができる
- プログラミングのスキル向上してより洗練されたブログラムが書けるようになる
■本のご紹介
プログラミング入門講座――基本と思考法と重要事項がきちんと学べる授業
こちらの本はプログラミング・スキルの重要性から、特徴そして学習サイトも紹介しています。その中でScratch(スクラッチ)のサイトでは子供でも楽しめるプログラミングが学べるようになっています。
今回の記事でご紹介した「データ構造」と「アルゴリズム」についても分かりやすく学べますので、ぜひ参考になさってください。
プログラミングにおけるデータ構造
データ構造とは、簡単に言えば「データの整理整頓の仕方」です。私たちの日常生活でも、物の整理整頓の仕方はたくさんありますよね。
- 本棚に本を並べる
- 引き出しに衣類を仕分ける
- 冷蔵庫に食材を収納する
これと同じように、コンピュータの中でもデータを効率的に扱うための「箱」のようなものが必要になります。それがデータ構造です。
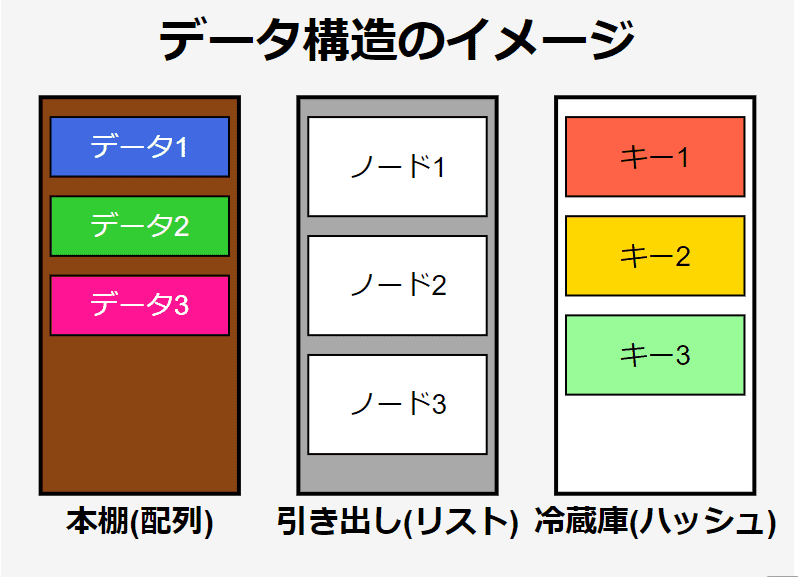
この図は、日常生活でのデータ整理とコンピュータのデータ構造の類似性を表しています。本棚、引き出し、冷蔵庫はそれぞれ異なるタイプのデータ構造を表現しています。
プログラミングでよく使われる代表的なデータ構造
プログラミングでよく使われるデータ構造にはどんなものがあるのでしょうか?代表的なものを見ていきましょう。
この表は、各データ構造の特徴と簡単なイメージ図を示しています。実際のプログラミングでは、これらのデータ構造を適切に選択し、効率的にデータを扱います。
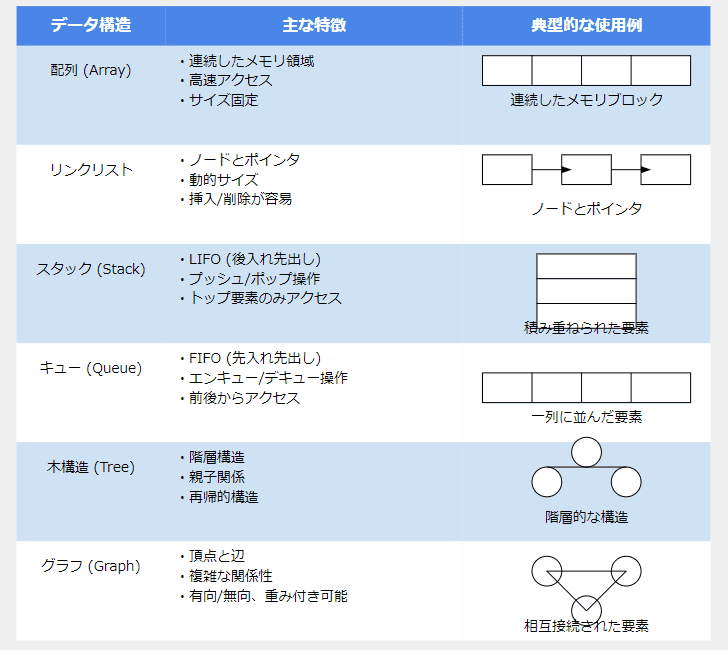
1. 配列(Array)
配列は、最も基本的なデータ構造の一つです。同じ型のデータを連続的にメモリ上に並べて格納します。
配列(Array)の特徴
- データへのアクセスが非常に高速
- サイズが固定されることが多い
- メモリ使用効率が良い
- データの挿入や削除が難しい(特に中間位置の場合)
- インデックス(添字)を使って直接データにアクセスできる
- データの順序が重要な場合に適している
- 要素数が事前に分かっている場合に効果的
2. リンクリスト(Linked List)
リンクリストは、データとそのデータが次のデータを指す情報(ポインタ)をセットにした構造です。
リンクリスト(Linked List)の特徴
- データの追加や削除が容易
- メモリを効率的に使用できる
- データへのアクセスに時間がかかる(特に後ろの方のデータ)
- 各要素がメモリ上で連続している必要がない
- データの挿入や削除が頻繁に行われる場合に適している
- サイズが動的に変化するデータ構造が必要な場合に有用
- 順序付きのデータを扱う際に使用される
3. スタック(Stack)
スタックは、後入れ先出し(LIFO: Last-In-First-Out)の原則に基づくデータ構造です。
スタック(Stack)の特徴
- データの追加(プッシュ)と取り出し(ポップ)を一方の端からのみ行う
- 最後に追加されたデータが最初に取り出される
- データの追加と削除が非常に高速
- 関数呼び出しの管理
- 式の評価(逆ポーランド記法など)
- アルゴリズムの実装(深さ優先探索など)
4. キュー(Queue)
キューは、先入れ先出し(FIFO: First-In-First-Out)の原則に基づくデータ構造です。
キュー(Queue)の特徴
- データの追加を一方の端から、取り出しを反対側の端から行う
- 最初に追加されたデータが最初に取り出される
- データの順序が保持される
- タスクスケジューリング
- データバッファ
- 幅優先探索アルゴリズムの実装
5. 木構造(Tree)
木構造は、親子関係を持つデータの集まりを表現するデータ構造です。
木構造(Tree)の特徴
- 階層的なデータを表現するのに適している
- 一つの親ノードが複数の子ノードを持つことができる
- データの検索、挿入、削除が比較的高速
- ファイルシステムの構造表現
- 組織図や家系図の表現
- 効率的な検索アルゴリズム(二分探索木など)の実装
6. グラフ(Graph)
グラフは、頂点(ノード)と辺(エッジ)で表現される最も汎用的なデータ構造です。
グラフ(Graph)の特徴
- 複雑な関係性を表現できる
- 方向性のある辺(有向グラフ)と方向性のない辺(無向グラフ)がある
- 辺に重みを付けることができる(重み付きグラフ)
- ソーシャルネットワークの表現
- 地図や経路探索システム
- ネットワークトポロジーの表現
これらのデータ構造は、それぞれ異なる特性と用途を持っています。プログラミングにおいて、適切なデータ構造を選択することは、効率的なアルゴリズムの設計と実装に直結します。問題の性質や操作の頻度に応じて、最適なデータ構造を選びましょう。
プログラミングのアルゴリズム
それでは、アルゴリズムについて見ていきましょう。アルゴリズムって聞くと難しそうですが、実は私たちの日常生活の中にもたくさんのアルゴリズムが存在しています。
アルゴリズムとは、簡単に言えば「問題を解決するための手順」のことです。例えば、料理のレシピも一種のアルゴリズムと言えます。
- 材料を準備する
- 野菜を切る
- フライパンを熱する
- 具材を炒める
- 調味料を加える
- 盛り付ける
これらの手順を順番に実行することで、おいしい料理ができあがりますよね。プログラミングのアルゴリズムも同じような考え方です。ある問題を解決するために、どのような手順を踏めば効率的に目的を達成できるか、それを考えるのがアルゴリズムなんです。
この図は、料理のレシピをアルゴリズムとして表現したものです。各ステップが順番に実行され、最終的に目的(おいしい料理)が達成されることを示しています。
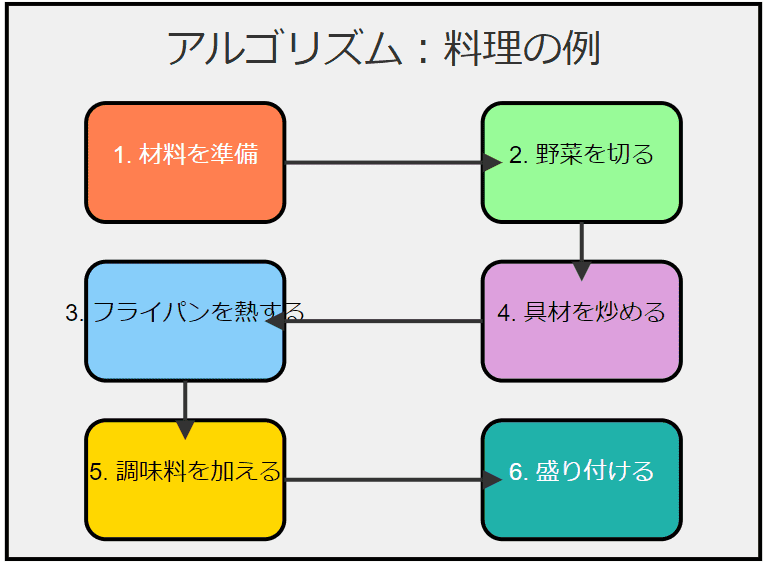
代表的なアルゴリズム
プログラミングの世界には、様々な問題を解決するための代表的なアルゴリズムがあります。ここでは、理解しやすいいくつかのアルゴリズムを紹介します。
この表は、各アルゴリズムの特徴と簡単な例を示しています。実際のプログラミングでは、これらのアルゴリズムを適切に選択し、効率的に問題を解決していきます。
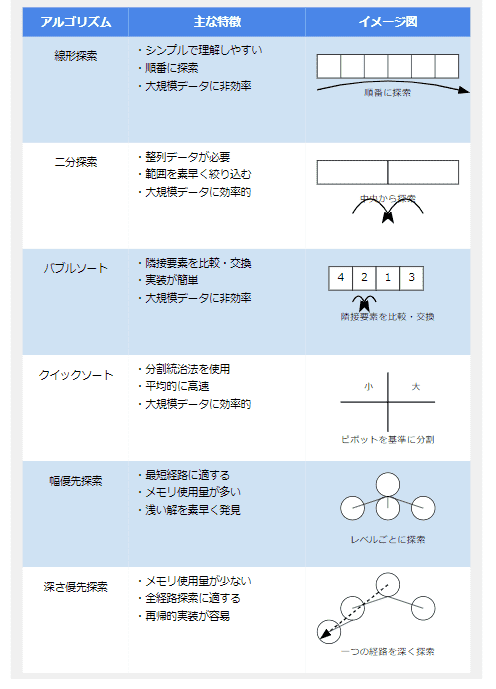
1. 線形探索(Linear Search)
線形探索は、データの集合の中から特定の要素を見つけ出す最もシンプルな方法です。この方法では、データの先頭から順番に一つずつ調べていきます。探している要素が見つかるまで、または全てのデータを確認し終わるまでこの作業を続けます。
線形探索の特徴
- とてもシンプルで理解しやすい
- 小さなデータ集合に適している
- データが整列されていなくても使える
- 大きなデータ集合では時間がかかる
- 小規模なデータセットでの要素検索
- 整列されていないデータでの検索
- シンプルな検索機能の実装
- データベースの単純な検索操作
2. 二分探索(Binary Search)
二分探索は、あらかじめ整列されたデータに対して使用できる効率的な探索方法です。この方法では、探索範囲の中央にある値を調べ、探している値がそれより大きいか小さいかによって、探索範囲を半分に絞っていきます。
二分探索の特徴
- データが整列されている必要がある
- 探索範囲を素早く絞り込める
- 大きなデータ集合でも効率的に探索できる
- データの追加や削除が頻繁にある場合は不向き
- 大規模な整列済みデータでの高速検索
- 辞書やデータベースでの効率的な検索
- 数値の平方根の近似値計算
- 競技プログラミングでの時間効率の良い解法
3. バブルソート(Bubble Sort)
バブルソートは、データを整列するための単純なアルゴリズムです。隣り合う2つの要素を比較し、順番が逆なら入れ替える操作を、整列が完了するまで繰り返します。
バブルソートの特徴
- 理解と実装が簡単
- 小さなデータ集合には適している
- 大きなデータ集合では非常に非効率
- データの交換回数が多い
- 教育目的でのソートアルゴリズムの説明
- 小規模データセットの簡易的な整列
- アルゴリズムの効率性比較の基準
- メモリ使用量が制限される環境での簡易ソート
4. クイックソート(Quick Sort)
クイックソートは、「分割統治法」を用いた効率的なソートアルゴリズムです。データの中から基準値(ピボット)を選び、それより小さい要素と大きい要素に分割し、それぞれの部分に対して同じ操作を再帰的に適用します。
クイックソートの特徴
- 大規模なデータ集合に対して非常に効率的
- 平均的に高速なパフォーマンスを示す
- 実装が比較的複雑
- 最悪の場合の性能が悪い
- 大規模データセットの高速ソート
- プログラミング言語の標準ライブラリでのソート実装
- データベースシステムでの大量データ整列
- 並列処理を利用した効率的なソート
5. 幅優先探索(Breadth-First Search, BFS)
幅優先探索は、グラフや木構造のデータを探索するアルゴリズムです。現在の位置から到達可能な全ての場所を調べ、そこからさらに到達可能な場所を順番に探索していきます。
幅優先探索の特徴
- 最短経路問題を解くのに適している
- 探索範囲が広がるにつれてメモリ使用量が増加する
- グラフの全ての頂点を訪れることができる
- 深さの浅い解を見つけるのに効果的
- 最短経路問題の解決(迷路、ナビゲーションなど)
- ソーシャルネットワークの分析(友人関係の深さなど)
- ウェブクローリング
- パズルゲームの最適解探索
6. 深さ優先探索(Depth-First Search, DFS)
深さ優先探索も、グラフや木構造のデータを探索するアルゴリズムです。一つの経路をできるだけ深く探索し、行き詰まったら一つ戻って別の経路を探索します。
深さ優先探索の特徴
- メモリ使用量が比較的少ない
- 全ての可能な経路を探索できる
- 深い階層にある解を見つけるのに効果的
- 再帰的なアルゴリズムで実装しやすい
- 迷路生成アルゴリズム
- トポロジカルソート(依存関係の解決)
- サイクル検出(循環参照の発見など)
- ゲーム木の探索(チェスAIなど)
これらのアルゴリズムは、それぞれ異なる状況や問題に適しています。適切なアルゴリズムを選択することで、効率的な問題解決が可能になります。実際のプログラミングでは、問題の性質や扱うデータの特性に応じて、最適なアルゴリズムを選択しましょう。
データ構造とアルゴリズムの関係
ここまでデータ構造とアルゴリズムについて個別に見てきましたが、実はこの2つには深い関係があります。
データ構造は「データをどのように整理するか」を決めるもので、アルゴリズムは「そのデータをどのように処理するか」を決めるものです。つまり、適切なデータ構造を選ぶことで、アルゴリズムの効率が大きく変わってくるんです。
例えば、大量のデータの中から特定の要素を探す場合を考えてみましょう。
- 配列を使用した線形探索
- ソート済み配列を使用した二分探索
- ハッシュテーブルを使用した探索
1.配列を使用した線形探索
同じデータ型の要素を連続したメモリ領域に格納する構造
- データ構造:配列
- アルゴリズム:線形探索
- 特徴:実装は簡単だが、データ量が多いと探索に時間がかかる
2.ソート済み配列を使用した二分探索
配列の先頭から順に各要素を調べ、目的の要素を見つける
- データ構造:ソート済み配列
- アルゴリズム:二分探索
- 特徴:探索は高速だが、データの追加・削除に時間がかかる
3.ハッシュテーブルを使用した探索
- データ構造:ハッシュテーブル
- アルゴリズム:ハッシュ関数による直接アクセス
- 特徴:探索が非常に高速で、データの追加・削除も比較的速い
このように、同じ「データの探索」という問題でも、使用するデータ構造によって適したアルゴリズムが変わり、その結果として処理の効率が大きく変わってきます。
■プログラミングスクールのご紹介
こちらの記事ではプログラミングスクール8校を厳選してご紹介しています。今回のデータ構造とアルゴリズムの理解にまだ不安が残っているならば、スクールに行き疑問点を解決するという選択もあります。少し行き詰ったとな感じたら参考にしてお問い合わせしてみてください。

初めてのデータ構造とアルゴリズム|プログラミング初心者向け:まとめ

- データ構造は、データを効率的に扱うための「箱」のようなもの。
- アルゴリズムは、問題を解決するための手順。
- データ構造とアルゴリズムは密接な関係にある。
いかがでしたでしょうか?データ構造とアルゴリズムは、最初は難しく感じるかもしれません。でも、これらの基礎を理解することで、より効率的で洗練されたプログラムを書けるようになります。1つひとつ記事を繰り返し確認することで知識もより深まるでしょう。

